Agentic RAG: Building and Evaluating Agentic Retrieval
From my master’s thesis in Artificial Intelligence.
Retrieval-Augmented Generation
Large language models are useful for a huge range of tasks, but less reliable when an answer depends on specific or domain-specific information. Retrieval-Augmented Generation (RAG) helps by retrieving relevant documents and handing them to the model as context, but it searches once and stops, so if that search misses the right document the answer is wrong no matter how capable the model is.

Agentic Retrieval
Agentic retrieval, also called Agentic RAG, adds reasoning to the search itself. It grades whether the results answer the question, rewrites the query and tries again when they don’t, and reorders the results before returning them. This works better, but the extra steps add time and cost. My thesis asks whether agentic retrieval is worth that, and when a simpler search is already good enough.
The Agentic System
The design follows ideas that are already common in the agentic RAG literature. A grader that judges whether the retrieved set is good enough is the core idea behind Corrective RAG. Using a language model to reorder a list of candidates comes from RankGPT. The loop that ties retrieval, grading, and rewriting together sits in the tradition of tool-using agents like ReAct. I combined these into one pipeline. A search returns a set of candidate documents, a grader checks whether they answer the question, and if not, a rewriter reformulates the query and the search runs again. The loop stops once the grader is satisfied or after a fixed number of rounds, and a final step reorders the results before they are returned.
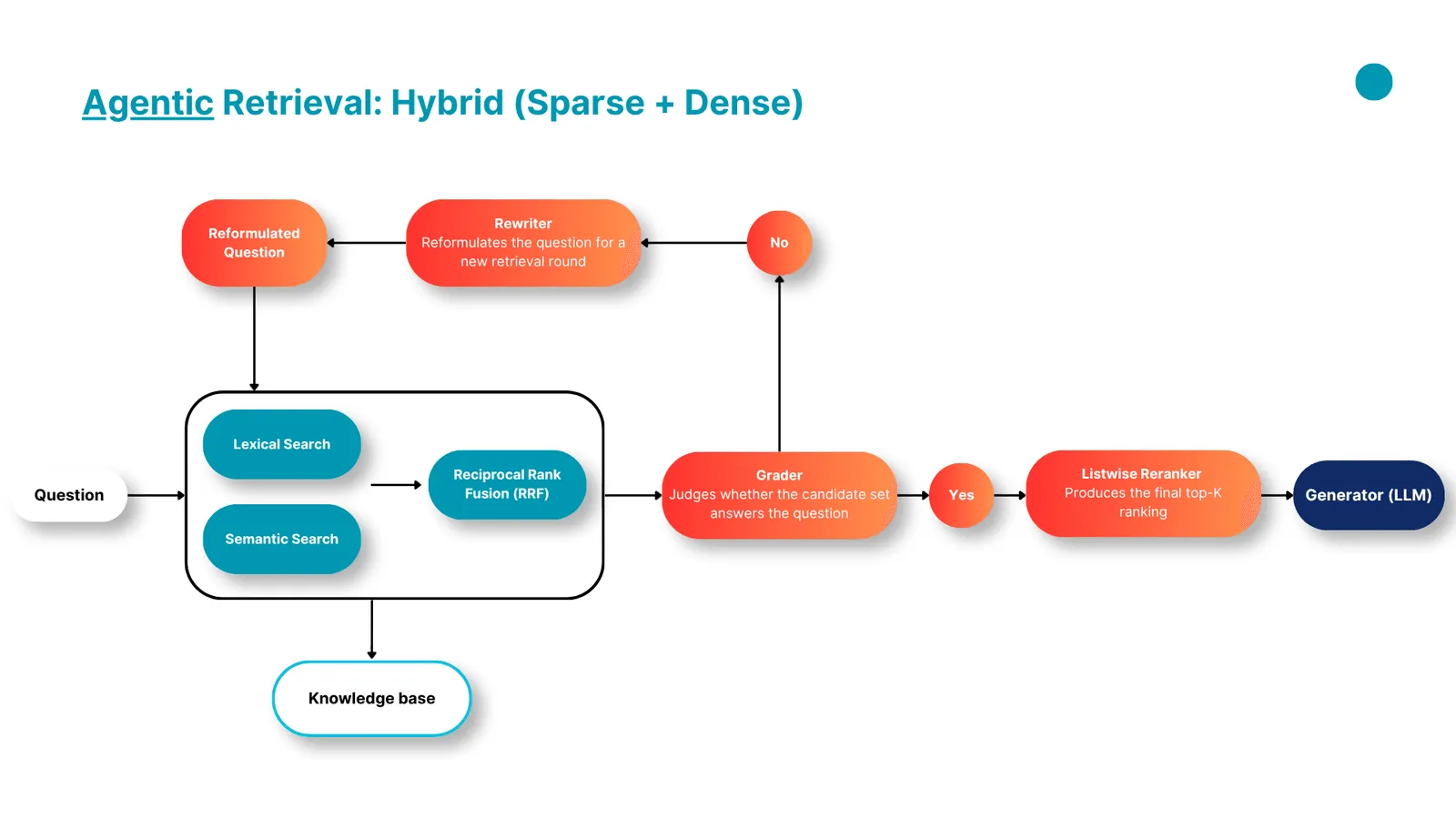
The system is built in Python with LangGraph, a framework for wiring language-model steps into an explicit graph of nodes and edges. It sits at a low enough level that every decision the pipeline makes is visible in the graph rather than hidden inside a prebuilt agent, which made the system easier to measure and to compare fairly against the simpler versions. The same loop wraps three common kinds of search underneath, one based on keyword matching, one based on meaning, and a hybrid of the two, so the only thing changing between them is the search itself.
The Wix Dataset
Everything was tested on WixQA, a public benchmark built from the Wix Help Center, the support knowledge base that real Wix users search when building or fixing a website. It pairs questions with the help articles that actually answer them, which is what makes it possible to score whether a search found the right one. The questions come in two sets, one written by real users and one drawn from chatbot conversations, so the same system can be checked against two different ways people phrase their problems.
 Wix is an intuitive, cloud-based website builder that lets you create and manage professional websites without needing coding or web design experience.
Wix is an intuitive, cloud-based website builder that lets you create and manage professional websites without needing coding or web design experience.
 The Wix Help Center, which WixQA is built from. The task is to find the right article for a given question.
The Wix Help Center, which WixQA is built from. The task is to find the right article for a given question.
Results and findings
On average, wrapping the search in the agentic loop improved result quality by around 12 to 13 percent, and the gain held up under statistical testing. More searches improved than declined, by roughly two to one, and the ones that did improve tended to improve by a wide margin, the right document was usually sitting outside the top results until the loop or reordering step pulled it up. Not every search benefited though, some that were already correct got reshuffled and came out worse, which points to the real design question of knowing in advance which searches are worth the extra effort.
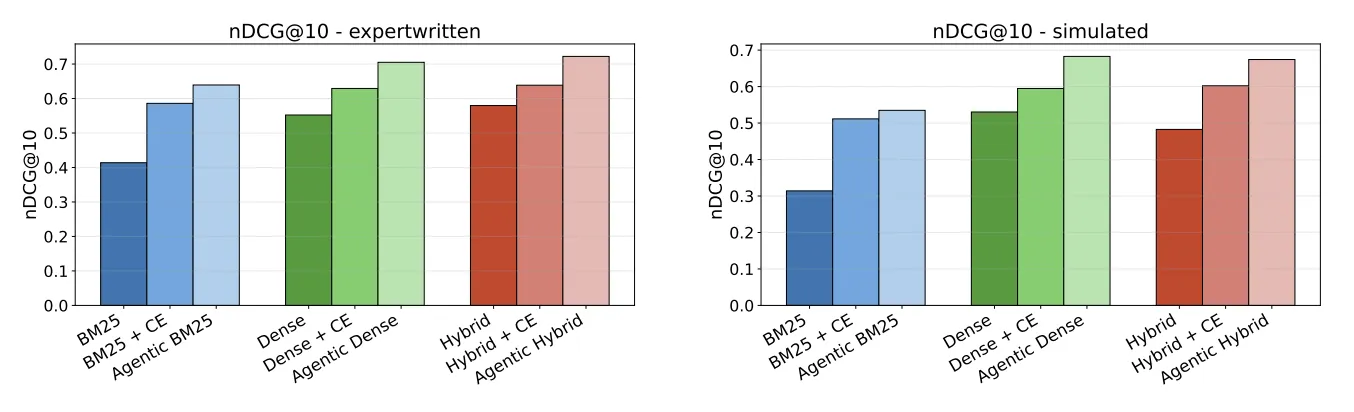 Result quality across the three search types, each shown as a plain baseline, a baseline with an extra reordering step, and the full agentic pipeline. The agentic version is highest in every group.
Result quality across the three search types, each shown as a plain baseline, a baseline with an extra reordering step, and the full agentic pipeline. The agentic version is highest in every group.
None of this is free either. The agentic loop adds latency and model-call cost on every search, whether or not it ends up helping, which matters once you’re operating at the volume a busy help center handles rather than a handful of test queries.
Links
Read the full study and find the code and experiments here, https://github.com/MaiHenry/evaluating-agentic-retrieval